Master the sensor data management process to turn raw data into actionable insights. Discover key strategies for IT professionals!

Sensor Data Management Process for IT Professionals

TL;DR:
- Sensor data management requires careful schema organization, time synchronization, and optimized pipelines to ensure data usefulness. Implementing dedicated metadata tables, high-performance storage formats, and AI-driven data quality improvements enhances real-time analytics. A disciplined, well-structured approach at the ingestion and processing stage is crucial for scalable, reliable sensor network operations.
Sensor networks are generating data faster than most organizations can process it. A typical 50-sensor deployment produces approximately 50GB of raw data in just six months, and that volume only grows as infrastructure scales. For data analysts and IT professionals, the real challenge is not collecting the data. It is structuring the sensor data management process so that what comes out the other end is actually useful for real-time decisions, anomaly detection, and long-term reporting.
Table of Contents
- Key Takeaways
- Requirements for efficient sensor data management
- Processing and storing raw sensor data
- Optimizing sensor data pipelines for low latency
- AI and synthetic data in sensor data analytics
- Common pitfalls and how to fix them
- My take on where sensor data management is actually headed
- How Beyondsensor supports your sensor data operations
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Separate metadata from time-series rows | Store sensor metadata in a linked table, not embedded in each row, to prevent redundancy and simplify schema changes. |
| Clean before you store | Removing duplicates and unwanted fields before ingestion reduces storage costs and improves downstream query performance. |
| Indexing reduces latency measurably | Advanced indexing architectures like DyGLIN cut query latency by over 26%, which matters in real-time analytics pipelines. |
| AI synthetic data cuts development time | Technologies like SensorGPT reduce real-world training data requirements from 80% to 10%, accelerating model deployment. |
| Time synchronization is non-negotiable | Hardware-level NTP/PPS synchronization prevents temporal mismatches that silently corrupt sensor data analysis. |
Requirements for efficient sensor data management
Before you write a single line of pipeline code, your infrastructure and data schema decisions will either make or break everything downstream. Getting these right is the highest-leverage investment you can make.
Hardware and software baseline
Processing raw sensor streams on underpowered hardware is one of the most common and costly mistakes. Single-core processing of a 50-sensor dataset takes 22 to 28 minutes per wrangling task. That is manageable for a one-time run, but completely unsustainable at production scale. At minimum, your processing environment needs multi-core CPUs, sufficient RAM (32GB or more for datasets exceeding 10GB), and a time-series database purpose-built for high-write throughput, such as InfluxDB, TimescaleDB, or Apache IoTDB.
On the software side, your stack needs to handle ingestion, transformation, and query with minimal friction. The table below shows a common baseline for teams just getting structured:
| Component | Tool options | Notes |
|---|---|---|
| Message broker | MQTT, Apache Kafka | Kafka preferred for high-throughput streams |
| Time-series storage | InfluxDB, TimescaleDB | Both support time-based indexing natively |
| Transformation layer | Apache Spark, Pandas | Spark for distributed; Pandas for moderate scale |
| Metadata management | PostgreSQL, SQLite | Linked via sensor_id to time-series table |
| Visualization | Grafana, Kibana | Connect directly to time-series DBs |
Metadata and time synchronization
One of the most consistently mishandled parts of the sensor data lifecycle is metadata placement. Embedding facility or device metadata directly into each time-series row creates schema redundancy and query bloat. The correct approach is maintaining a separate metadata table and linking records through a unique sensor_id. This keeps your time-series table lean and makes schema updates trivial rather than catastrophic.

Time synchronization deserves equal attention. Hardware NTP/PPS synchronization should be treated as a core engineering requirement, not an afterthought. Timestamp drift between sensors in the same network creates correlation errors that compound over time and are notoriously difficult to debug retroactively.
Pro Tip: Set up your metadata schema before you onboard a single sensor. Retrofitting a schema onto millions of existing rows is an order of magnitude harder than designing it correctly from day one.
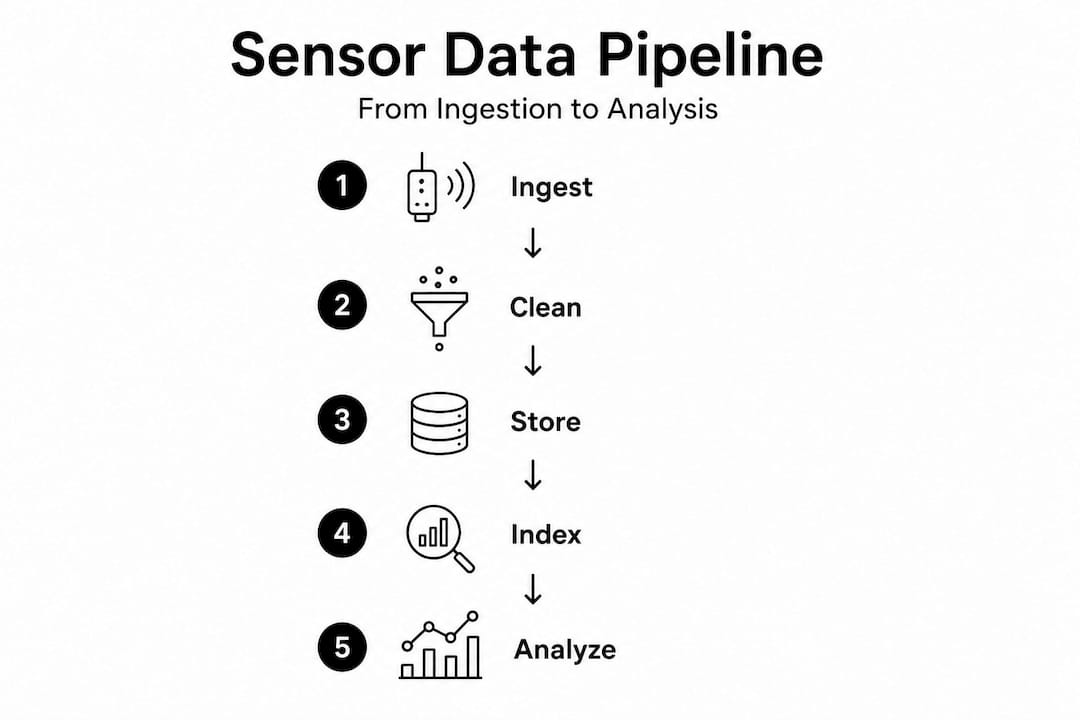
Processing and storing raw sensor data
With your infrastructure in place, the next phase of the sensor data management process focuses on what happens to raw data between ingestion and storage. This is where most analysts either build a clean foundation or inherit a permanent headache.
Cleaning raw sensor data
Raw sensor output is rarely production-ready. Typical raw datasets contain roughly 2% duplicate rows and fields that are never queried downstream. Leaving those in place wastes storage and slows every query that touches the table. Your cleaning pipeline should execute these steps in order:
- Remove duplicates. Use timestamp and sensor_id as the composite key. Any row matching both fields exactly is a duplicate.
- Drop unused fields. Audit your schema against actual query patterns. If a field has not been used in three months, it probably should not be in the primary table.
- Handle anomalies. Flag statistical outliers (values beyond 3 standard deviations of a rolling window) rather than deleting them. Deletion destroys forensic value.
- Resample for aggregation. Convert raw 100ms readings to 1-second or 1-minute summaries based on your analytics requirements. This dramatically reduces row count without losing signal.
- Validate timestamps. Cross-check ingestion time against device-reported timestamps. Discrepancies above your defined threshold should trigger an alert, not silent acceptance.
Storage format and architecture decisions
The storage format you choose determines how fast your queries run and how much you pay for disk. Here is a direct comparison of the most common architectures for sensor data teams:
| Storage approach | Pros | Cons | Best for |
|---|---|---|---|
| Time-series DB (InfluxDB) | Native time indexing, fast range queries | Limited relational joins | High-frequency telemetry |
| Columnar store (Parquet on S3) | Excellent compression, cheap at scale | Slower for real-time queries | Historical batch analytics |
| Relational DB (PostgreSQL + TimescaleDB) | Full SQL, good for metadata joins | Requires tuning for write performance | Mixed workloads |
| Hybrid (InfluxDB + Parquet archive) | Best of both worlds | Higher operational complexity | Enterprise-scale pipelines |
Pro Tip: Archive data older than 90 days to compressed Parquet files automatically. Time-series databases are optimized for recent data. Keeping cold data in them costs money and slows down your hot queries.
Optimizing sensor data pipelines for low latency
Once your cleaning and storage layers are solid, the focus shifts to query performance and pipeline responsiveness. This is where sensor data optimization moves from theory into measurable gains.
Indexing for high-frequency streams
Standard B-tree indexes perform poorly on high-frequency sensor streams because write volume constantly fragments the index. Learned index architectures address this directly. The DyGLIN framework, for example, reduces query latency by 26.4% and improves insertion throughput by 30%. The trade-off is an 18.5% increase in memory overhead, which is acceptable for most production deployments given the retrieval gains.
The core principle is matching your index architecture to your read/write ratio. If you are ingesting continuously at high frequency and querying at moderate rates, a read-optimized learned index pays for itself quickly.
Edge processing and pipeline resilience
Filtering noise at the edge before data hits your central broker is one of the highest-impact data management strategies available. High-frequency electrical noise can create artificial data spikes that overwhelm message brokers and cause downstream database failures. Signal conditioning at the sensor or gateway level removes this noise before it becomes a storage problem.
For pipeline resilience, these practices make the most consistent difference:
- Implement watermarking to handle out-of-order and late-arriving packets. Systems that assume strict arrival ordering produce inaccurate state estimation without any obvious errors.
- Define SLAs for latency and accuracy at the pipeline design stage, not during incident response. This gives your team a clear threshold to monitor and alert against.
- Partition your ingestion topics by sensor group in Kafka to prevent a single noisy sensor from degrading throughput across the entire pipeline.
- Use backpressure mechanisms in your stream processor to avoid memory overflow during traffic spikes.
Systems that assume strict arrival-time ordering lead to inaccurate state estimation. Watermarking is not optional in any pipeline where sensor timestamps and ingestion timestamps can diverge by more than a few seconds.
Pro Tip: Profile your pipeline under peak load before go-live. A pipeline that handles 10,000 messages per second smoothly in testing often collapses at 12,000 in production due to undiscovered memory constraints.
AI and synthetic data in sensor data analytics
The most significant shift in sensor data management right now is not in storage technology. It is in how teams generate the training data needed to build reliable machine learning models on top of their sensor pipelines.
TDK's SensorGPT technology illustrates the direction the field is heading. It reduces reliance on real-world training data from 80% to 10%, cutting model development time from months to weeks. For teams managing industrial or security sensor networks, this matters because acquiring labeled real-world sensor data at scale is expensive, slow, and sometimes physically impossible.
Practical ways AI is changing the sensor data management process today:
- Synthetic anomaly generation. Generate rare fault signatures that would never appear in sufficient volume from live sensors alone, giving models genuine exposure to edge cases.
- Automated data quality scoring. ML classifiers flag low-confidence sensor readings before they enter the analytics layer, reducing manual review overhead.
- Drift detection for calibration. Calibration drift degrades static ML models over time. AI-powered monitoring detects performance degradation before it affects production decisions.
- Edge AI model compression. Deploying lightweight inference models at the edge reduces the volume of raw data transmitted to central systems, which cuts bandwidth costs and ingestion load simultaneously.
Exploring how AI analytics intersect with sensor operations reveals how far these techniques have matured beyond academic research. They are deployable today in industrial and security environments.
Pro Tip: Start synthetic data generation with your rarest failure modes, not your most common ones. Common events are well-represented in real data. Your model's weakest point is always the scenario it has seen least.
Common pitfalls and how to fix them
Even well-architected sensor data pipelines fail in predictable ways. Recognizing these patterns early saves significant remediation effort.
The most frequent issues and their practical fixes:
- Metadata embedded in time-series rows. This creates storage bloat and schema rigidity. Move metadata to a linked table immediately and use sensor_id as the foreign key.
- No analog signal conditioning. Electrical noise spikes that reach your message broker can triple your data volume in minutes. Add hardware filters or gateway-level software conditioning.
- Loose time synchronization standards. Treat timestamp accuracy as a first-class requirement. Implement NTP synchronization across all sensor nodes and audit drift weekly.
- Ignoring memory overhead in index selection. The 18.5% memory cost of advanced indexing is manageable. Discovering it after deployment is not.
- No data quality dashboard. Without visibility into duplicate rates, null field percentages, and ingestion lag, problems accumulate silently.
Use this checklist to verify system health before declaring any pipeline production-ready: duplicate row rate below 0.5%, all sensor timestamps within 100ms of NTP reference, metadata schema versioned and documented, anomaly flagging active on all input fields, and storage growth rate within projected bounds.
Pro Tip: Run a quarterly sensor data audit that checks schema drift, index efficiency, and storage costs simultaneously. These three metrics together tell you almost everything about pipeline health.
My take on where sensor data management is actually headed
I have worked with enough sensor deployments to say with confidence that the most common mistake is not technical. It is sequencing. Teams spend months optimizing their query layer while running on a metadata schema that was designed in an afternoon. The index architecture cannot save you if the data going in is poorly labeled and inconsistently timestamped.
My experience has consistently reinforced one counterintuitive point: more data is not better data. Organizations that collect at maximum frequency on every channel and store everything indefinitely tend to produce worse analytics than teams that are deliberate about sampling rates, field selection, and retention policies. Quality controls applied early in the pipeline compound their benefits across every downstream use case.
The shift toward edge AI is real and it is accelerating. But I think the honest advice is to get your ingestion, cleaning, and metadata architecture right before you add model inference to the equation. A well-structured data foundation makes AI integration straightforward. A messy one makes it fragile and expensive to maintain.
The organizations that will manage sensor data best in the next three years are not the ones with the most sophisticated models. They are the ones with the most disciplined pipelines. Scalability and maintainability beat cleverness every time.
— Eumir
How Beyondsensor supports your sensor data operations
Beyondsensor builds the tools and AI-backed infrastructure that data teams and security operations need to move from raw sensor output to confident decisions. Whether you are managing physical security networks, industrial monitoring systems, or smart infrastructure, the pipeline complexity is real and the stakes are high.
For system integrators deploying sensor networks across multiple sites, Beyondsensor provides architecture guidance, hardware-software validation, and analytics integration tailored to regional compliance requirements across Southeast Asia. For security agencies that depend on real-time sensor data analytics for threat detection and response, Beyondsensor's AI solutions deliver the accuracy and speed your operations require. Explore the full range of sensor management tools available to find what fits your deployment.
FAQ
What is the sensor data management process?
The sensor data management process covers the full pipeline from ingestion through cleaning, storage, indexing, and analytics. It includes metadata organization, time synchronization, anomaly handling, and query optimization to produce reliable, usable data.
How do I reduce query latency in sensor data pipelines?
Use a read-optimized indexing architecture such as DyGLIN, which reduces query latency by 26.4% compared to standard B-tree indexes. Also partition ingestion topics by sensor group and archive cold data to columnar storage formats.
Why does time synchronization matter in sensor data analytics?
Timestamp errors are the leading cause of correlation failures in multi-sensor pipelines. Hardware NTP/PPS synchronization keeps all sensor timestamps aligned, preventing state misestimation and inaccurate analytics outputs.
How can AI improve sensor data management?
AI accelerates model development through synthetic data generation, automates data quality scoring, and detects calibration drift before it affects decisions. Technologies like SensorGPT reduce real-world training data requirements by up to 90%.
What is the best way to handle sensor metadata?
Store metadata in a separate table linked to your time-series data via a unique sensor_id. Embedding metadata directly in time-series rows creates redundancy, slows queries, and makes schema updates unnecessarily complex.
Recommended
- Sensing tools guide: Types, accuracy, and security uses | News | BeyondSensor
- Step-by-Step Security Integration: Advanced Sensor Guide | News | BeyondSensor
- Top sensor security tips for safety & compliance 2026 | News | BeyondSensor
- Optimize physical security workflows with advanced sensors | News | BeyondSensor
Read More Articles

Why Edge Computing in Security Matters in 2026
Discover why edge computing in security is crucial in 2026. Learn how real-time processing can enhance your security strategy significantly.

Infrastructure Surveillance Integration Guide for Facilities
Explore this comprehensive infrastructure surveillance integration guide to learn how to optimize your facility's security with expert insights and top tools.

Automation Challenges Checklist for Project Managers
Discover key hurdles in your projects with our automation challenges checklist. Identify risks early and ensure successful deployments.

Sensor Integration Step by Step: A Project Manager's Guide
Discover the sensor integration step by step process for successful project management. Master the phases to ensure reliable performance!
Let's Build YourSecurity Ecosystem.
Whether you're a System Integrator, Solution Provider, or an End-User looking for trusted advisory, our team is ready to help you navigate the BeyondSensor landscape.
Direct Advisory
Connect with our regional experts for tailored solutioning.