Enhance your team's preparedness with this security monitoring workflow guide. Learn essential phases and best practices for effective incident response.

Security Monitoring Workflow Guide for Facility Teams

TL;DR:
- A security monitoring workflow is a continuous process that detects, analyzes, and responds to incidents across an organization. Following established frameworks like the NIST incident response lifecycle improves team performance and ensures ongoing risk management.
A security monitoring workflow is a continuous, structured process that detects, analyzes, responds to, and learns from security incidents across an organization. Security professionals and facility managers who follow a defined workflow, grounded in frameworks like the NIST incident response lifecycle and ISO/IEC 27035, consistently outperform teams that rely on ad hoc responses. This security monitoring workflow guide covers the essential phases, SOC alert triage mechanics, tool selection, detection tuning, and multi-source integration that together form a repeatable, audit-ready operation.

What are the essential phases of a security monitoring workflow?
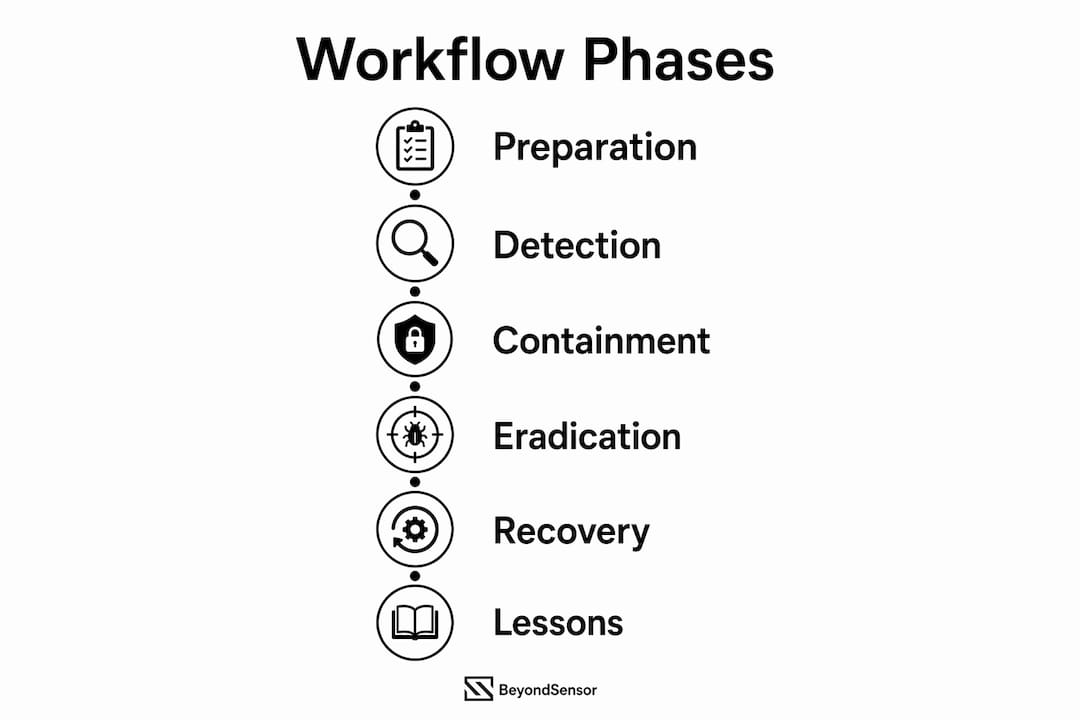
The NIST incident response lifecycle defines four phases that form the backbone of any effective monitoring workflow: Preparation, Detection and Analysis, Containment/Eradication/Recovery, and Post-Incident Activity. NIST frames this as a continuous cycle tied directly to cybersecurity risk management, not a one-time sequence. That distinction matters. Teams that treat incident response as a project with a finish line miss the ongoing feedback that makes detection sharper over time.
Preparation covers everything before an incident occurs: building playbooks, configuring detection rules, training analysts, and establishing communication protocols. Without solid preparation, the Detection and Analysis phase collapses under pressure. Detection and Analysis is where alerts are generated, correlated, and assessed for severity and confidence.
The iterative nature of containment is often underestimated. During Containment and Eradication, analysts continue detection activities to identify additional compromised hosts. This means the Detection and Analysis phase does not end when containment begins. It runs in parallel, feeding new findings back into the response.
Post-Incident Activity closes the loop. Lessons learned sessions produce documented findings that update playbooks, refine detection rules, and improve preparation for the next cycle. NIST views incident response as integral to cybersecurity risk management, reinforcing that workflows must continuously evolve to reduce risk.
- Preparation: Build playbooks, assign roles, configure tooling, and establish baselines.
- Detection and Analysis: Collect telemetry, generate alerts, triage, and assess severity.
- Containment, Eradication, and Recovery: Isolate affected systems, remove threats, restore operations, and continue detection in parallel.
- Post-Incident Activity: Document findings, update playbooks, and feed improvements back into Preparation.
Pro Tip: Schedule a lessons-learned session within 72 hours of closing a significant incident. Memory fades fast, and delayed reviews produce generic takeaways that don't improve detection rules.
How does a typical SOC alert lifecycle work?
The SOC alert lifecycle is the operational engine inside the Detection and Analysis phase. Each alert passes through detection, first triage to determine whether it is malicious, benign, or unclear, investigation if needed, and then either closure or escalation to formal incident handling. Most alerts close as benign. That reality makes efficient triage the single most important factor in SOC throughput.
The lifecycle steps in sequence are:
- Alert generation: A SIEM, EDR, or sensor triggers an alert based on a detection rule or behavioral anomaly.
- Central queueing: Alerts land in a shared queue, visible to Tier 1 analysts.
- Triage: Analysts classify the alert using available context. Triage is the most time-sensitive stage, and delays here create backlogs that bury genuine threats.
- Investigation: Alerts classified as unclear or suspicious escalate to Tier 2 or Tier 3 for deeper analysis.
- Response: Confirmed incidents trigger a formal response workflow, including containment actions and stakeholder notification.
- Closure and documentation: Every alert, whether benign or malicious, receives a documented disposition that feeds detection tuning.
Categorizing alerts by threat type and attack stage using the MITRE ATT&CK framework gives analysts a shared language for prioritization. Tier 1 handles high-volume, lower-complexity alerts. Tier 2 and Tier 3 focus on confirmed or complex cases. This tiering prevents specialist analysts from spending time on noise.
Alert intake is separated from incident activation by design. Only alerts that meet defined confidence and impact thresholds trigger a formal incident response. Engaging the full incident response team on unconfirmed alerts wastes resources and lowers response effectiveness over time.
Pro Tip: Define explicit escalation criteria in writing before you go live with a new detection rule. Ambiguous escalation thresholds are the leading cause of alert burial in high-volume SOC environments.
What tools and data sources does a security monitoring workflow need?
The right toolset determines whether your workflow can scale. Four platform categories form the core of most modern security monitoring operations.
| Tool Category | Primary Function | Example Platforms |
|---|---|---|
| SIEM | Centralized log collection, correlation, and alerting | Splunk, Microsoft Sentinel, IBM QRadar |
| EDR | Endpoint telemetry, behavioral detection, and isolation | CrowdStrike Falcon, SentinelOne, Microsoft Defender |
| XDR | Cross-layer correlation across endpoint, network, and cloud | Palo Alto Cortex XDR, Trend Micro Vision One |
| SOAR | Workflow automation, playbook execution, and case management | Palo Alto XSOAR, Splunk SOAR, Swimlane |
Telemetry coverage is as important as the tools themselves. A workflow that monitors only endpoints misses lateral movement across the network and identity abuse in cloud environments. Effective physical security workflows add sensor-based inputs, including access control events, video analytics, and environmental alarms, to the telemetry mix.
Detection rule tuning is where most teams lose ground. Writing detection rules before establishing baselines causes manual triage backlogs and alert fatigue, leading to missed critical alerts. Baseline normal behavior first, then activate rules against that baseline. This sequence is not optional. It is the difference between a detection system analysts trust and one they learn to ignore.
Comprehensive documentation at every stage, capturing context, severity, rationale, and analyst decisions, supports chain-of-custody requirements, compliance audits, and playbook updates. Documentation is an operational asset, not administrative overhead.
How should teams tune and improve their monitoring workflows?
Treating the security monitoring workflow as a continuous loop with integrated improvement steps produces stronger operational performance and faster threat detection. The loop runs: Prepare, Monitor, Triage, Investigate, Respond, Improve, and back to Prepare. Each cycle should produce at least one concrete change to a detection rule, playbook, or escalation threshold.
- Establish baselines first. Map normal traffic volumes, login patterns, and process behaviors before activating any behavioral detection rule. Baselining normal behaviors before rule activation is critical to minimizing false positives and maintaining analyst trust.
- Automate enrichment, not decisions. Use SOAR platforms to auto-enrich alerts with threat intelligence, asset context, and historical data. Reserve auto-closing for only the highest-confidence, lowest-risk alert categories. Automated decisions on ambiguous alerts create blind spots.
- Run structured feedback sessions. After each significant alert or incident, analysts should document what the detection rule caught, what it missed, and whether the escalation path was correct. Feed those findings directly into rule updates.
- Measure triage speed and accuracy separately. Fast triage that misclassifies threats is worse than slow triage that gets it right. Track both metrics and set targets for each independently.
- Review playbooks quarterly. Threat actor tactics change. A playbook written for a ransomware variant from 18 months ago may not address current techniques mapped in MITRE ATT&CK. Quarterly reviews keep response procedures current.
Modern SOC architecture uses AI-assisted orchestration to automate first-line triage, enrich alerts with context, correlate events, suppress noise, and execute response steps within defined guardrails. Automation improves throughput by removing bottlenecks and enabling specialist analysts to focus on high-confidence cases. The goal is not to replace analyst judgment. It is to protect analyst attention.
How do you integrate human reporting with technical telemetry?
Technical telemetry alone does not capture the full picture. Facility managers and security teams that rely exclusively on automated sensors miss incidents that employees, visitors, or helpdesk staff observe and report first. Integrating detection signals from both technical telemetry and human reporting channels reduces detection delays and makes incident management more comprehensive.
Practical steps to merge both data streams include:
- Establish a single intake point. Route human reports from helpdesks, hotlines, and physical security staff into the same triage queue as automated alerts. Separate queues create separate blind spots.
- Apply the same triage criteria. A report from a staff member about a tailgating incident at a server room door deserves the same severity assessment as an EDR alert on that same floor. Consistent criteria prevent human reports from being deprioritized.
- Capture evidence at intake. Collect timestamps, reporter identity, location, and initial description at the moment of report. ISO/IEC 27035 requires tailored roles and workflows for effective incident handling and auditable evidence capture. Waiting to document until after investigation loses critical context.
- Cross-reference with technical data. A human report of suspicious behavior near a network closet should immediately trigger a review of access logs, camera feeds, and network traffic from that location and time window.
"Multi-channel capture aligned with ISO/IEC 27035 incident management process phases ensures auditable incident records and reduces the risk of detection gaps that single-source monitoring cannot close."
Integrating telemetry and human reporting into a coordinated workflow is one of the highest-leverage improvements a facility security team can make. The technology exists. The gap is usually process design.
Key Takeaways
A security monitoring workflow succeeds only when preparation, triage, multi-source detection, and structured post-incident review operate as a single continuous loop rather than separate activities.
| Point | Details |
|---|---|
| Follow the NIST lifecycle | Use Preparation, Detection and Analysis, Containment, and Post-Incident Activity as your repeatable cycle. |
| Prioritize triage speed and accuracy | Define escalation criteria in writing before activating detection rules to prevent alert burial. |
| Baseline before you build rules | Establish normal behavior patterns first to minimize false positives and protect analyst trust. |
| Merge human and technical inputs | Route staff reports and automated alerts into a single triage queue with consistent severity criteria. |
| Document every decision | Capture context, rationale, and outcomes at each stage to support audits and playbook improvement. |
Why most security monitoring workflows stall at triage
I have seen well-resourced security teams with strong tooling still struggle because their workflow was designed as a flowchart, not a loop. The phases looked right on paper. The problem was that lessons learned never made it back into detection rules. Post-incident reviews produced slide decks, not rule updates. Within six months, the same alert types were generating the same false positive rates.
The fix is not more technology. It is accountability at the feedback stage. Someone on the team needs to own the connection between post-incident findings and detection rule changes. Without that ownership, the loop breaks at the most valuable point.
Alert fatigue is real, and it is almost always a baselining failure. Teams that activate behavioral detection rules before mapping normal behavior patterns create noise that analysts learn to dismiss. Once that dismissal habit forms, it is hard to reverse. The answer is to slow down rule deployment and invest in telemetry coverage and baseline accuracy first.
Documentation is the part most teams underinvest in, and it is the part that pays the highest long-term dividend. Comprehensive analyst records support chain-of-custody requirements, accelerate onboarding of new analysts, and give you the evidence base to justify workflow changes to leadership. Treat documentation as an operational tool, not a compliance checkbox.
— Eumir
How Beyondsensor supports your security monitoring operations
Security teams that need to close the gap between sensor-based telemetry and SOC-level alert management have a specific integration challenge. Beyondsensor's AI-powered security solutions are built for exactly that environment, connecting physical sensor inputs with automated enrichment and triage workflows that reduce analyst workload without removing human judgment from critical decisions.
Beyondsensor integrates with SIEM, EDR, and human reporting channels to create a unified data stream that feeds directly into your triage queue. The platform's AI-assisted orchestration handles first-line enrichment, correlates events across physical and digital telemetry, and flags high-confidence cases for analyst review. Security agencies and facility managers across Singapore, Malaysia, and the Philippines already use Beyondsensor's advanced sensing tools to improve detection accuracy and reduce response times across their operations.
FAQ
What is a security monitoring workflow?
A security monitoring workflow is a structured, repeatable process that covers detection, triage, investigation, response, and post-incident review. It is grounded in frameworks like the NIST incident response lifecycle and ISO/IEC 27035.
How does SOC alert triage work?
Triage is the classification of an alert as malicious, benign, or unclear using available context, with escalation to Tier 2 or Tier 3 analysts for alerts that require deeper investigation. It is the most time-sensitive step in the SOC alert lifecycle.
What tools are needed for security monitoring?
Core tools include a SIEM for log correlation, an EDR for endpoint telemetry, an XDR for cross-layer detection, and a SOAR platform for workflow automation and playbook execution.
Why does baselining matter for detection accuracy?
Activating behavioral detection rules without first establishing normal behavior baselines produces high false positive rates that erode analyst trust and cause genuine threats to be missed.
How does ISO/IEC 27035 apply to facility security teams?
ISO/IEC 27035 requires organizations to define tailored roles and workflows for incident handling and to capture auditable evidence records. It does not mandate specific tools, making it applicable across both physical and cyber security environments.
Recommended
- Optimize physical security workflows with advanced sensors | News | BeyondSensor
- Remote Sensor Monitoring Guide for Decision-Makers | News | BeyondSensor
- Industrial Sensor Integration Workflow: 2026 Engineer's Guide | News | BeyondSensor
- How to Secure Facilities with Advanced Sensor Technology | News | BeyondSensor
Read More Articles

What Is Smart Infrastructure? A 2026 Guide for Planners
Discover what smart infrastructure is and how it integrates technology to enhance urban planning. Unlock the future of city management today!

What Is Multi-Sensor Integration for Security Pros
Discover what is multi-sensor integration and how it enhances security systems. Learn to implement it correctly for optimal performance.

Sensor Deployment Guide for Security Professionals 2026
Master efficient monitoring with our sensor deployment guide. Transform signals into actionable intelligence with expert insights for security professionals.

Why Edge Computing in Security Matters in 2026
Discover why edge computing in security is crucial in 2026. Learn how real-time processing can enhance your security strategy significantly.
Let's Build YourSecurity Ecosystem.
Whether you're a System Integrator, Solution Provider, or an End-User looking for trusted advisory, our team is ready to help you navigate the BeyondSensor landscape.
Direct Advisory
Connect with our regional experts for tailored solutioning.